Prenons l'exemple d'une fonction dans un programme. Cette fonction peut appeler d'autres fonctions qui à leurs tours appellent d'autres fonctions (qui elles même appellent des fonctions, etc.). Comment savoir et se souvenir de l'ordre d'appels, de qui appelle qui, et où retourner une fois la fonction appelée terminée ? Une première réponse pourrait être de stocker toutes ces informations dans un simple tableau, mais comment le parcourir ? Où insérer les nouvelles données ? Comment enlever les éléments inutiles (lorsqu'une fonction a finie d'être exécutée) ?
Toutes ces questions nous amènent à penser qu'il nous faut une structure de données organisée, bien définie et qui puisse gérer cette idée d'imbrication : la pile.
Une pile (stack en anglais) est une structure de données de type LIFO (Last In First Out, dernier arrivé premier sorti). Elle fonctionne exactement comme une pile d’assiettes :
C’est le principe LIFO, lorsqu’on ajoute un élément sur une pile il est en haut, et lorsqu’on retire un élément on prend le dernier ajouté (celui tout en haut).
L’action d’ajouter un élément dans la pile est appelée : empiler (ou push en anglais) :
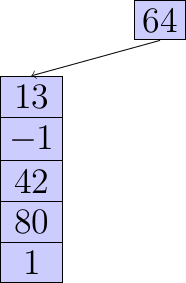
L’action d’enlever un élément de la pile est appelée : dépiler (ou pop en anglais) :

Pour représenter une pile, je vais vous présenter deux moyens :
Comme pour une liste chaînée, il existe différentes fonctions de bases permettant de manipuler une pile.
créerPile :
Initialiser la pile à NULL
supprimerPile :
Pour chaque élément de la pile
Supprimer l'élément actuel
empiler (élément) :
Faire pointer le haut de la pile vers le nouvel élément
dépiler :
Sauvegarder les données de l'élément en haut de la pile
Supprimer l'élément en haut
Faire pointer le haut de la pile vers NULL
Retourner les données sauvegardées
estVide :
Si le premier élément de la pile est NULL
Retourner vrai
Sinon
Retourner fauxcréerPile :
Créer un tableau d'une taille fixe et suffisamment grand pour la pile
Initialiser le pointeur de pile (PP) à 0
supprimerPile :
Supprimer le tableau
empiler (élément) :
Affecter les données du nouvel élément à la case d'index PP du tableau
Incrémenter le PP
dépiler :
Décrémenter le PP
Retourner les données de l'élément d'index PP du tableau
estVide :
Si PP = 0
Retourner vrai
Sinon
Retourner fauxSoit \(N\) le nombre d'éléments de la pile.
créerPile : \(O(1)\)supprimerPile : \(O(N)\)empiler : \(O(1)\)dépiler : \(O(1)\)estVide : \(O(1)\)#include <stdio.h>
#include <stdlib.h>
typedef struct Noeud Noeud;
struct Noeud
{
Noeud *suivant;
int donnee;
};
typedef Noeud *Pile;
void creerPile(Pile *pile)
{
*pile = NULL;
}
void supprimerPile(Pile *pile)
{
Noeud *iPile;
for(iPile = *pile; iPile != NULL; ) {
Noeud *temp;
temp = iPile->suivant;
free(iPile);
iPile = temp;
}
}
void empiler(Pile *pile, int donnee)
{
Noeud *nouveau;
nouveau = malloc(sizeof(Noeud));
nouveau->suivant = *pile;
nouveau->donnee = donnee;
*pile = nouveau;
}
int depiler(Pile *pile)
{
Noeud *temp;
int donnee;
temp = (*pile)->suivant;
donnee = (*pile)->donnee;
free(*pile);
*pile = temp;
return donnee;
}
int estVide(Pile *pile)
{
if(*pile == NULL)
return 1;
else
return 0;
}
int main(void)
{
Pile pile;
creerPile(&pile);
empiler(&pile, 42);
// 42
empiler(&pile, 9);
// 9
// 42
int retour = depiler(&pile);
// retour = 9
supprimerPile(&pile);
return 0;
}Le code est simple et ne nécessite pas d’explication, si besoin je vous invite à relire l'article sur les listes chaînées pour bien comprendre le code.
#include <stdio.h>
#define TAILLE_MAX 256
int pile[TAILLE_MAX];
int PP;
void creerPile(void)
{
PP = 0;
}
void empiler(int donnee)
{
pile[PP] = donnee;
++PP;
}
int depiler(void)
{
--PP;
return pile[PP];
}
int estVidePile(void)
{
if(PP == 0)
return 1;
else
return 0;
}
int main(void)
{
creerPile();
empiler(42);
// 42
empiler(9);
// 9
// 42
int retour = depiler();
// retour = 9
return 0;
}Cette implémentation est facile à comprendre et à utiliser.
Si vous programmez en C++, la STL (Standard Template Library) fournit une implémentation et des fonctions permettant de manipuler une pile : http://www.cplusplus.com/reference/stack/stack/
La pile est donc une structure de données facile à implémenter et peut être pratique dans de nombreux domaines :