Si vous suivez régulièrement les nouvelles dans le domaine de
l'informatique, vous êtes sans doute déjà tombé sur un article parlant
d'un programme utilisant le principe d'apprentissage artificiel (ou
machine learning en anglais) afin de résoudre efficacement une
tâche qui parait compliquée voire impossible pour un ordinateur. Si ce
n'est pas le cas, il suffit de taper "machine learning" dans un moteur
de recherche et regarder les résultats dans la section "actualités" pour
apercevoir un nombre impressionnant d'articles récents à ce propos et
sur des thèmes très variés. Mais qu'est-ce que l'apprentissage
artificiel ? Dans quel domaine peut-on l'appliquer ? Et surtout quels
sont concrètement les algorithmes mis en place par ce type
d'apprentissage ?
Principe
En général, lorsqu'on cherche à résoudre un problème avec un
ordinateur, on lui demande de réaliser une suite d'opérations bien
précise pour avoir une sortie voulue. Cependant, dans certains cas il
est très compliqué de définir cette suite d'opérations pour un problème
donné, même si nous sommes capables en tant qu'humain de le résoudre
sans difficulté. Par exemple, essayez de décrire à votre machine comment
reconnaître un visage sur une photo, pour l'ordinateur l'image n'est
qu'un amas de pixels, et la notion de visage ne lui évoque rien du tout,
cependant vous êtes capable instantanément de le faire et cela depuis
tout petit. Le but de l'apprentissage artificiel n'est pas de décrire
directement des opérations afin de résoudre un problème, mais plutôt de
donner la capacité à l'ordinateur d'apprendre à résoudre ce problème par
lui-même. Pour apprendre, il va procéder comme vous et
moi lorsqu'on essaie de s'améliorer dans une discipline, c'est-à-dire en
essayant, en échouant, et en adaptant sa stratégie dans le but d'être
meilleur la prochaine fois.
L'apprentissage artificiel (ou parfois appelé apprentissage
automatique) désigne un domaine de l'intelligence artificielle
visant à reproduire un comportement spécifique à partir
de données. Ce comportement est en général créé de
toute pièce, et sera ensuite amélioré automatiquement lors du processus
d'apprentissage.
On peut alors comprendre à quel point ce domaine est intéressant vu
la complexité aujourd'hui d'automatiser certaines tâches (d'autant plus
qu'on a accès rapidement à énormément de données grâce à Internet,
rendant l'apprentissage toujours plus efficace). Cependant,
l'apprentissage artificiel n'est pas uniquement utilisé pour automatiser
une tâche complexe qu'un humain peut faire, mais il est aussi capable
d'atteindre des niveaux d'efficacité bien supérieurs à ceux d'un humain
(et c'est là tout l'intérêt de la discipline).
Type d'apprentissage
Il existe de nombreuses manières de faire apprendre quelque chose à
votre ordinateur, et il faudra choisir la plus adaptée en fonction du
but de votre intelligence artificielle. Voici quelques exemples de
différentes méthodes :
Apprentissage supervisé : pour reprendre le
problème de détection de visage, on pourrait fournir à notre ordinateur
des centaines (ou milliers) de photos en précisant nous même où se
trouve le visage. L'ordinateur va ensuite essayer de généraliser et
créer un modèle à partir de l'entrée fournit afin de
pouvoir deviner par la suite où se situe un visage sur une nouvelle
photo. Cet apprentissage est dit supervisé car on fournit à l'ordinateur
des exemples de problèmes qu'il doit résoudre, mais
aussi leurs solutions correspondantes afin qu'il
établisse des liens entre ces derniers.
Apprentissage non supervisé : on donne cette fois
ci à l'ordinateur uniquement les entrées, et on aimerait qu'il génère et
regroupe automatiquement les données dans différentes classes (qu'on
appelle aussi étiquette). Par exemple, vous avez une
liste d'articles de journaux que vous aimeriez trier en fonction du
sujet abordé dedans, l'idée serait que votre algorithme regroupe les
articles discutant d'un sujet commun ensemble. L'entrée serait alors les
articles, tandis que les sorties seraient les catégories auxquelles
appartiennent les différents articles. Ici, notre algorithme ne reçoit
pas les solutions des problèmes qu'on lui pose, mais seulement l'énoncé,
et c'est à lui d'essayer de trouver une solution. Ceci peut être très
utile quand nous même nous ne connaissons pas la solution, ou bien qu'on
tente de trouver une nouvelle approche intéressante à laquelle on n'a
pas pensé avant.
Apprentissage semi-supervisé : l'entrée contient un
mélange des deux dernières méthodes, c'est-à-dire des entrées avec des
sorties correspondantes et d'autres sans. L'intérêt est dans un premier
temps de réduire la charge de travail sur le traitement des données
lorsqu'on a des entrées colossales (attribuer une sortie à chaque entrée
peut être long et fastidieux, voire nécessiter des moyens importants
pour décider de la sortie). De plus, cela peut améliorer radicalement
l'efficacité de l'apprentissage (grâce à un entraînement plus diversifié
comprenant en général peu de sorties attribuées pour beaucoup d'entrées
sans sorties correspondantes). Imaginez que vous êtes un médecin
cherchant à détecter des tumeurs, il peut être très couteux de faire des
analyses sur des milliers voir millions de patients pour entraîner une
intelligence artificielle (sans même prendre en compte le temps
nécessaire à l'opération), et donc il serait plus pratique de fournir à
votre algorithme quelques études très détaillées ainsi que des analyses
sans réponses afin qu'il construise un modèle de prédiction.
Apprentissage par renforcement : ce dernier diffère
des autres dans le sens où il ne reçoit pas d'entrées (au sens
d'exemples d'un problème), ni de sorties, mais plutôt la description
d'un environnement dans lequel il peut évoluer grâce à
différentes actions ayant un certain
impact sur ses futures décisions. Un exemple
d'apprentissage par renforcement serait un algorithme
génétique, qui consiste à reproduire le comportement de la nature à
travers une sélection naturelle afin de faire évoluer des
agents chargés de fonctionner dans l'environnement
choisi. Un exemple concret serait un jeu vidéo, ce dernier contient un
environnement défini ainsi que plusieurs actions qui ont des
répercussions sur notre agent. Il y a beaucoup d'exemples d'intelligence
artificielle qui apprenne à jouer à un jeu vidéo, comme : Super Mario
World, Flappy
Bird, Pong/Tetris,
2048, ou même le jeu
caché intégré dans Chrome, etc.
Problèmes à résoudre
Avec ces différents types d'apprentissages apparait plusieurs
algorithmes, mais avant de comprendre comment fonctionnent ces
algorithmes, cherchons à savoir ce qu'ils essaient de résoudre. Il y a
plusieurs problèmes importants dans le domaine de l'apprentissage
artificiel, en voici une liste non exhaustive :
Classification : on cherche à attribuer plusieurs
entrées une classe bien précise (dans un apprentissage
supervisé donc, car notre algorithme aura reçu un entraînement composé
d'entrées et de leurs classes correspondantes), ces classes peuvent être
par exemple dans le cadre d'une description d'une image : "animal",
"paysage", "montagne", "forêt", etc.
Régression : les valeurs obtenues dans un problème
de régression sont des valeurs numériques, par exemple
l'estimation du prix d'un appartement en fonction de différents critères
comme sa taille, son emplacement géographique, le nombre de pièces, son
ancienneté, etc. Là aussi, ce problème se pose dans un apprentissage
supervisé.
Partitionnement (ou clustering en anglais)
: on veut que l'algorithme sépare les entrées en différents groupes
distincts (appelés cluster en anglais), mais c'est à
l'algorithme de décider des groupes à attribuer aux entrées. Ceci est
donc un problème dans le domaine de l'apprentissage non supervisé.
L'apprentissage artificiel utilise les mathématiques afin de résoudre
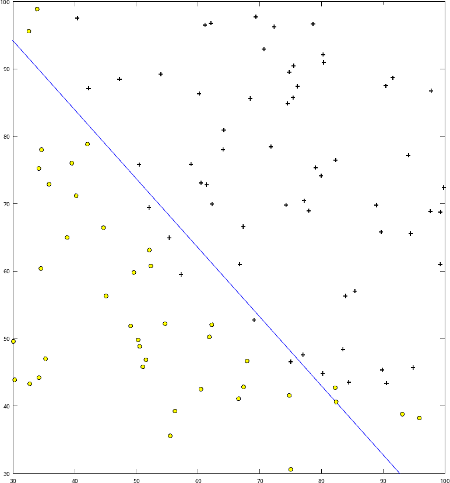
ces problèmes, par exemple un exercice de classification pourrait être
représenté graphiquement par la séparation efficace (grâce à une ligne,
courbe, etc.) de deux ensembles distincts :
Exemple de classification
Les deux paramètres de l'entrée sont l'axe x et l'axe y, et les
sorties sont les classes correspondantes (rond ou croix).
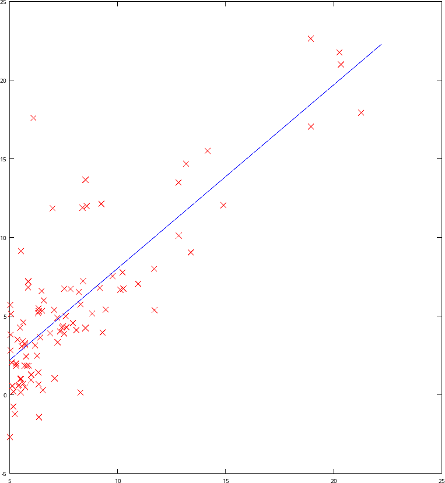
Dans un problème de régression, on cherchera par exemple à
généraliser l'entrée (l'axe x dans notre cas) à l'aide d'une fonction,
ici elle est linéaire, mais on peut trouver des fonctions polynomiales
complexes pour créer des modèles plus sophistiqués :
Exemple de régression
Ce modèle nous permettra de générer une sortie (l'axe y) sur de
nouveaux paramètres, en utilisant la fonction calculée (ici elle sera
donc de la forme \(y = ax + b\)).
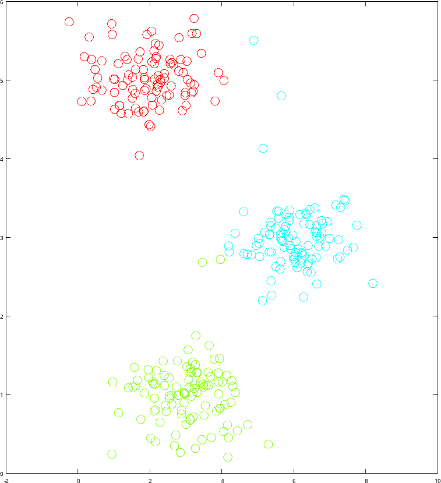
Enfin, un exemple de partitionnement serait de regrouper des points
entre eux, et de les différencier en groupe, comme ici avec trois
différents clusters (rouge, bleu, et vert) :
Exemple de partitionnement
Domaine d'application
L'apprentissage artificiel est présent partout :
Médecine : afin de faire des diagnostics, un
ordinateur peut être un atout majeur car il a accès à des milliers
d'exemples de patients et peut ainsi effectuer un diagnostic
automatiquement et relativement précis sur le type de maladie, son
avancement, etc. (ex : Watson
une intelligence artificielle développée par IBM qui a des utilisations
multiples, et notamment dans la médecine).
Moteur de recherche : la plupart des moteurs de
recherches modernes utilisent des algorithmes de machine learning autant
pour comprendre la requête de l'utilisateur, que pour la chercher ou
encore trier les résultats en fonction de la pertinence.
Communication : la reconnaissance vocale, ou la
compréhension d'un message écrit sont des problèmes extrêmement
complexes à résoudre, et pourtant grâce à l'apprentissage artificiel, on
arrive parfois à des résultats assez impressionnant de précision hors
normes. Hound avait fait
beaucoup de bruit en 2015 grâce à une vidéo qui
démontrait une efficacité incroyable comparée à ses autres concurrents
(Siri, Google Now, Cortana, etc.).
Traitement d'images : que ce soit pour reconnaître
un visage, ou décrire une image, l'apprentissage artificiel est souvent
indispensable vu la complexité de la tâche. Facebook a par exemple un
algorithme terriblement efficace de reconnaissance de visage (DeepFace),
grâce au nombre colossal de photos envoyées sur la plateforme en ligne
(servant alors d'exemple et d'entraînement à l'algorithme). Ce dernier
est tellement puissant qu'il est même capable de vous reconnaître
lorsque vous ne regardez pas la caméra, quand vous avez le visage
partiellement couvert, ou bien encore quand vous êtes de dos. Google a
aussi développé un programme
capable de faire une description très précise d'une image ce qui est
assez bluffant pour un ordinateur vu la complexité de certaines
images.
Internet : la plupart des réseaux sociaux
(Facebook, Twitter, ...), des sites de ventes (Amazon, Ebay, ...), de
divertissement (Netflix, Deezer, Spotify, ...) utilisent des algorithmes
d'apprentissage artificiel pour vous faire des recommandations, des
suggestions, afin de mieux comprendre vos goûts (qui est une notion trop
abstraite pour être entièrement décrite et précisée à un ordinateur,
d'où l'utilisation d'une intelligence artificielle).
Transport : la fameuse Google
Car est une voiture totalement autonome et sans conducteur
développée par Google, qui a dépassé le stade de test et roule
aujourd'hui sur les routes de Californie. C'est impressionnant de voir à
quel point on peut aller loin avec la technologie de l'apprentissage
artificiel.
Sécurité : pour vérifier l'identité de quelqu'un,
d'une transaction bancaire ou de l'authenticité d'un mail, les
algorithmes de machine learning sont très utiles dans la sécurité et
permettent d'identifier rapidement les fraudes éventuelles. Tous les
bons clients mails sont capables de filtrer automatiquement les "spams"
et tous les systèmes bancaires sont aussi équipés de ce genre de
protection afin d'éviter des échanges douteux voire illicites.
La liste des exemples de tous les jours pourrait continuer
longtemps, mais on retrouve aussi cette forme
d'intelligence artificielle dans des applications plus surprenantes et
très intéressantes :
Art : est-ce que vous pensez savoir différencier
une peinture faite par un homme de celle réalisée par un ordinateur ?
Faites-le test, vous pourriez
être surpris de voir à quel point c'est difficile. Les ordinateurs
savent assez bien imiter des artistes, que ce soit dans la peinture
(avec l'exemple précèdent, ou encore DeepArt un outil permettant de copier le
style d'un peintre), dans la musique (EMI),
dans la littérature (écriture
de livres automatique), etc. Un ordinateur peut donc imiter avec une
précision incroyable un phénomène s'il est fourni assez de données.
Jeu : depuis qu'un ordinateur a battu le champion
du monde d'échec en 1997,
la compétition entre humain et ordinateur est rude. Le jeu de Go était
l'un des derniers jeux classiques à résister à cause de son nombre quasi
infini de possibilité (contrairement au jeu d'échec, où Deep Blue
explorait la plupart des possibilités et choisissait simplement la
"meilleure"), cependant en mars 2016, AlphaGo une
intelligence artificielle développée par Google a vaincu le champion du
monde grâce à plusieurs algorithmes d'apprentissage artificielle ainsi
qu'un entraînement intensif de plusieurs années de recherche. Cette
prouesse technique a surpris bon nombre de spécialistes dans le domaine,
qui ne pensaient tout simplement pas atteindre un tel niveau
d'intelligence en 2016, et espéraient que le jeu de Go résisterait plus
longtemps à la machine.
Prédiction : connaître le passé est un moyen
intéressant de prévoir le futur, et le super-ordinateur Nautilus
a amassé des centaines de millions de différents articles datant des 30
dernières années ce qui lui a permis en 2011 de prévoir avec une
précision incroyable l'arrivée du printemps Arabe, ainsi que l'endroit
où se cachait Osama bin Laden.
Encore une fois, la liste peut continuer car les exemples ne manquent
pas.
Conclusion
L'apprentissage artificiel est donc un domaine extrêmement vaste de
l'intelligence artificielle, et qui est encore en plein développement
aujourd'hui. Ce dernier est particulièrement efficace lorsqu'on cherche
à résoudre un problème difficile à exprimer concrètement, et qu'on est
capable de regrouper des données assez importantes dessus, afin qu'un
ordinateur puisse apprendre par lui-même comment résoudre ce problème
(et parfois même bien plus efficacement qu'un humain). Avec des données
de plus en plus importantes et riches en informations, cette discipline
ne fait que s'améliorer d'années en années, et son utilisation ne fait
que s'élargir et se diversifier.
Cependant, cette forme d'intelligence ne sait pas tout faire et
nécessite toujours l'aide d'un humain afin de l'améliorer, de lui
fournir des données pertinentes, et l'idée d'une intelligence
artificielle autonome capable d'apprendre, communiquer et prendre des
décisions importantes en effraie plus d'un. Ceci a poussé à la création
d'une organisation très
particulière dans le but d'éviter des risques majeurs dûs à des
intelligences artificielles, et cette dernière est supportée par
plusieurs personnalités importantes comme Stephen
Hawking, ou encore Elon Musk. Même si
l'apprentissage artificiel, voire l'intelligence artificielle de manière
générale, peut nous apporter énormément d'améliorations et d'innovations
impensables dans la vie de tous les jours, ceci peut tout à fait
apporter de grands risques et une lettre
ouverte de la fondation Futur of Life dénonce
l'automatisation d'armes de guerre qui marquent selon eux "une troisième
révolution dans l'armement après la poudre à canon et le nucléaire". Les
États-Unis notamment utilisent déjà des intelligences artificielles afin
de remplacer les humains dans des programmes de drones, car les pilotes
étaient souvent affectés
mentalement et développaient des traumatismes les forçant à
arrêter.
L'avenir de cette discipline est cependant loin d'être sombre, et
beaucoup de projets ambitieux sont lancés avec des objectifs tous plus
fous les uns que les autres (imitation artificielle du cerveau humain,
le transhumanisme, transfert de conscience humaine dans des ordinateurs,
etc.).
Vu l'omniprésence de ce domaine aujourd'hui, et dans le futur, il est
important pour un programmeur d'en comprendre la base ainsi que les
principaux algorithmes afin de résoudre des problèmes d'apprentissage
artificiel.